As below, the problem is mentioned. ● N jobs are to be stored on a computer. ● Each job has a di-0 deadline and a pi-0 benefit. ● Pi is won when the job is done by the deadline. ● If it is processed for unit time on a computer, the job is done. ● There is only one computer available to process work. ● Just one job on the computer is processed at a time. ● A effective approach is a subset of J jobs such that each job is done by its deadline. A feasible solution with optimum benefit potential is an optimal solution. Example : Let n = 4, (p1,p2,p3,p4) = (100,10,15,27), (d1,d2,d3,d4) = (2,1,2,1) No. feasible solution processing sequence profit value i (1,2) (2,1) 110 ii (1,3) (1,3) or (3,1) 115 iii (1,4) (4,1) 127 iv (2,3) (2,3) 25 v (3,4) (4,3) 42 vi (1) (1) 100 vii (2) (2) 10 viii (3) (3) 15 ix (4) (4) 27 ● Consider the workers subject to the constraint that the resulting work sequence J is a feasible solution in the non-increasing order of earnings. ● The non-increasing benefit vector is in the example considered before, (100 27 15 10) (2 1 2 1) p1 p4 p3 p2 d1 d d3 d2 J = { 1} is a feasible one J = { 1, 4} is a feasible one with processing sequence ( 4,1) J = { 1, 3, 4} is not feasible J = { 1, 2, 4} is not feasible J = { 1, 4} is optimal Theorem: Let J be a set of K jobs and Σ = (i1,i2,….ik) be a permutation of jobs in J such that di1 ≤ di2 ≤…≤ dik. ● J is a feasible solution that can be processed in order without breaching any deadly jobs in J. Proof : ● If the jobs in J can be processed in order without violating any deadline by specifying the feasible solution, then J is a feasible solution. ● Therefore, we only have to show that if J is a feasible one, then ⁇ is a possible order in which the jobs can be processed. ● Suppose J is a feasible solution. Then there exists Σ1 = (r1,r2,…,rk) such that drj ≥ j, 1 ≤ j <k i.e. dr1 ≥1, dr2 ≥ 2, …, drk ≥ k. each job requiring an unit time Σ= (i1,i2,…,ik) and Σ 1 = (r1,r2,…,rk) Assume Σ 1 ≠ Σ. Then let a be the least index in which Σ 1 and Σ differ. i.e. a is such that ra ≠ ia. Let rb = ia, so b > a (because for all indices j less than a rj = ij). In Σ 1 interchange ra and rb. • Σ = (i1,i2,… ia ib ik ) [rb occurs before ra in i1,i2,…,ik] • Σ 1 = (r1,r2,… ra rb … rk ) i1=r1, i2=r2,…ia-1= ra-1, ia ≠ rb but ia = rb We know di1 ≤ di2 ≤ … dia ≤ dib ≤… ≤ dik. Since ia = rb, drb ≤ dra or dra ≥ drb. In the feasible solution dra ≥ a drb ≥ b ● Therefore, if ra and rb are exchanged, the resulting permutation Σ11 = (s1, ... sk) reflects an order with the least index in which Σ11 and Σ differ by one is increased. ● The jobs in Σ 11 can also be processed without breaking a time limit. ● Continuing in this manner, ⁇ 1 can be translated into ⁇ without breaching any time limit. ● The theorem is thus proven.
|
Algorithm Greedy (a, n) //a [1: n] contains the n inputs. { solution:= ø; //Initialize the solution. for i:=1 to n do { x:= Select(a); if Feasible(solution, x) then solution: = Union(Solution, x); } return solution; } |
|
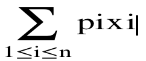
|
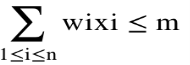
Let x[i] be the fraction taken from item i. 0 <= x[i] <= 1. The weight of the part taken from item i is x[i]*W[i] The Corresponding profit is x[i]*P[i] The problem is then to find the values of the array x[1:n] so that x[1]P[1]+x[2]P[2]+...+x[n]P[n] is maximized subject to the constraint that x[1]W[1]+x[2]W[2]+...+x[n]W[n] <= C Greedy selection policy: three natural possibilities
Policy 3 always gives an optimal solution.
|
|
|
|
| |
GREEDY ALGORITHM FOR JOB SEQUENCING WITH DEADLINE Procedure greedy job (D, J, n) J may be represented by // J is the set of n jobs to be completed // one dimensional array J (1: K) // by their deadlines // The deadlines are J ← {1} D (J(1)) ≤ D(J(2)) ≤ .. ≤ D(J(K)) for I 2 to n do To test if JU {i} is feasible, If all jobs in JU{i} can be completed we insert i into J and verify by their deadlines D(J®) ≤ r 1 ≤ r ≤ k+1 then J J← U{I} end if repeat end greedy-job Procedure JS(D,J,n,k) // D(i) ≥ 1, 1≤ i ≤ n are the deadlines // // the jobs are ordered such that // // p1 ≥ p2 ≥ ……. ≥ pn // // in the optimal solution ,D(J(i) ≥ D(J(i+1)) // // 1 ≤ i ≤ k // integer D(o:n), J(o:n), i, k, n, r D(0)← J(0) ← 0 // J(0) is a fictitious job with D(0) = 0 // K←1; J(1) ←1 // job one is inserted into J // for i ← 2 to do // consider jobs in non increasing order of pi // // find the position of i and check feasibility of insertion // r ← k // r and k are indices for existing job in J // // find r such that i can be inserted after r // while D(J(r)) > D(i) and D(i) ≠ r do // job r can be processed after i and // // deadline of job r is not exactly r // r ← r-1 // consider whether job r-1 can be processed after i // repeat if D(J(r)) ≥ d(i) and D(i) > r then // the new job i can come after existing job r; insert i into J at position r+1 // for I ← k to r+1 by –1 do J(I+1) J(l) // shift jobs( r+1) to k right by// //one position // repeat if D(J(r)) ≥ d(i) and D(i) > r then // the new job i can come after existing job r; insert i into J at position r+1 // for I k to r+1 by –1 do J(I+1) ← J(l) // shift jobs( r+1) to k right by// //one position // Repeat Complexity analysis : ● Let the number of jobs be n and the number of jobs used in the solution be s. ● The loop is iterated (n-1)times between lines 4-15 (the for-loop). ● Each iteration requires O(k) where k is the number of jobs that exist. ● The algorithm requires 0(sn) s ≤ n time, so 0(n2 ) is the worst case time. If di = n - i+1 1 ≤ i ≤ n, JS takes θ(n2 ) time D and J need θ(s) amount of space.
|
i: 1 2 3 4 P: 5 9 4 8 W: 1 3 2 2 C= 4 P/W: 5 3 2 4 Solution: 1st: all of item 1, x[1]=1, x[1]*W[1]=1 2nd: all of item 4, x[4]=1, x[4]*W[4]=2 3rd: 1/3 of item 2, x[2]=1/3, x[2]*W[2]=1 Now the total weight is 4=C (x[3]=0) |
//p[1:m] and w[1:n] contain the profits and weights respectively of the n objects ordered //such that p[i]/w[i]>= p[i+1]/w[i+1]. m is the knapsack size and x[1:n] is the solution vector. { for i:=1 to n do x[i]:= 0.0; //initialize x. U:= m; for i:=1 to n do { if(w[i]>U) then break; x[i]:=1.0; U:=U-w[i]; } if(i<=n) then x[i]:= U/w[i]; }
|
//E is the set of edges in G cost (1:n,1:n) is the adjacency matrix such at cost (i,j) is a +ve //real number or cost (i,j) is ∞ if no edge (i,j) exists. A minimum cost spanning tree is //computed and stored as a set of edges in the array T (1:n-1,1:2). (T(i,1), T(i,2) is an edge //in minimum cost spanning tree. The final cost is returned. { Let (k,l) to be an edge of minimum cost in E; mincost ß cost (k,l); (T(1,1) T(1,2) )ß (k,l); for iß 1 to n do // initialing near if cost (i,L) < cost (I,k) then near (i) ß L ; else near (i) ß k ; near(k) ß near (l) ß 0; for i ß 2 to n-1 do { //find n-2 additional edges for T Let j be an index such that near (J) ¹ 0 and cost (J, near(J)) is minimum; (T(i,1),T(i,2)) ß (j, NEAR (j)); mincost ß mincost + cost (j, near (j)); near (j) ß 0; for k ß 1 to n do // update near[] if near (k) ¹ 0 and cost(k near (k)) > cost(k,j) then NEAR (k) ß j; } return mincost; } |
//E is the set of edges in G. G has n vertices cost (u, v) is the cost of edge (u , v) t is //the set of edges in the minimum cost spanning tree and mincost is the cost. The //final cost is returned. { Construct the heap out of the edges cost using Heapify; for i:=1 to n do Parentß-1 //Each vertex is in the different set iß mincostß 0; While (i < n -1) and (heap not empty) do { delete a minimum cost edge (u,v) from the heap and reheapify using ADJUST; JßFIND (u); kßFIND (v); If j ≠ k then ißi+1 { T(i, 1) ß u; T (i,2) ßv; Mincost ß mincost + cost(u,v); union (j, k); }
} if (i ≠ n-1) then write(“no spanning tree”); else return minsort; } Complexities: ● The edges are maintained as a min heap. ● The next edge can be obtained / deleted in O(log e) time if G has e edges. ● Reconstruction of heap using ADJUST takes O(e) time. Kruskal’s algorithm takes O(e loge) time . Efficiency : Kruskal's algorithm's efficiency is dependent on the time taken to sort the edge weights of a given graph. ● With an effective algorithm for sorting: Efficiency: Θ(|E| log |E|)
|
Step 1. s.distance = 0; // shortest distance from s Step 2. mark s as “finished”; //shortest distance to s from s found Step 3. For each node w do Step 4. if (s, w) ϵ E then w.distance= Dsw else w.distance = inf; // O(N) Step 5. While there exists a node not marked as finished do // Θ(|N|), each node is picked once & only once Step 6. v = node from unfinished list with the smallest v.distance; // loop on unfinished nodes O(N): total O(N2) Step 7. mark v as “finished”; // why? Step 8. For each edge (v, w) ϵ E do //adjacent to v: Θ(|E|) Step 9. if (w is not “finished” & (v. distance + Dvw < w.distance) ) then Step 10. w.distance = v.distance + Dvw; // Dvw is the edge-weight from // current node v to w Step 11. w.previous = v; // v is parent of w on the shortest path end if; end for; end while; End algorithm
Complexity: (1) The while loop runs N-1 times: [Θ(N)], find-minimum-distance-node v runs another Θ(N) within it, thus the complexity is Θ(N2); Can you reduce this complexity by a Queue? (2) for-loop, as usual for adjacency list graph data structure, runs for |E| times including the outside while loop. Grand total: Θ(|E| + N2) = Θ(N2), as |E| is always ≤ N2. To store the priority queue, use an unordered array: Efficiency = x (n2). Store the priority queue using min-heap: Performance = O (m log n)
|




