|
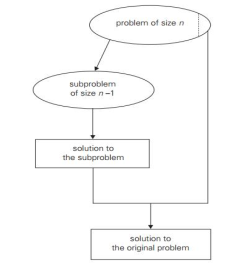
2. Decrease by a constant factor: On each iteration of the algorithm, this technique suggests decreasing a problem instance by the same constant factor. This constant factor is equivalent to two in most applications. A decrease by a factor other than two is extremely uncommon.
Algorithms that decrease by a constant factor are very effective, especially when the factor is greater than 2 as in the fake-coin problem. Example issues are given below:a. binary search and bisection method
|
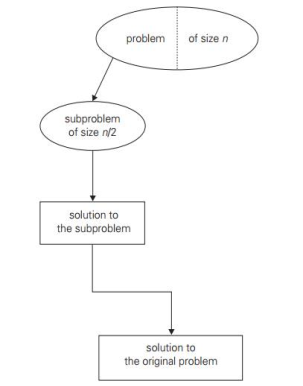
3. Variable size decrease: The size-reduction pattern in this variation differs from one iteration of an algorithm to another.
As the value of the second statement is always smaller on the right-hand side than on the left-hand side in the problem of finding gcd of two numbers, it does not decrease by either a constant or a constant element. Example issues are given below:a. Euclid ‘s algorithm Q2) Describe insertion sort?A2) Insertion Sort Insertion style is a decrease & conquer technique application. It is a sort based on comparison in which the sorted array is constructed on one entry at a time.Insertion sorting is a very basic process for sorting numbers in an ascending or descending order. The gradual method is accompanied by this method. It can be contrasted with the method of sorting cards at the time of playing a game.The numbers that are needed to be sorted are known as keys. Here is the insertion sort method algorithm. Algorithm:Algorithm: Insertion-Sort (A) for j = 2 to A.length key = A[j] // Insert A[j] into the sorted sequence A[1.. j - 1] i = j - 1 while i > 0 and A[i] > key A[i + 1] = A[i] i = i -1 A[i + 1] = key |
Using insertion sort to sort the following list of elements: 89, 45, 68, 90, 29, 34, 17 89 |45 68 90 29 34 17 45 89 |68 90 29 34 17 45 68 89 |90 29 34 17 45 68 89 90 |29 34 17 29 45 68 89 90 |34 17 29 34 45 68 89 90 |17 17 29 34 45 68 89 90 |
BFS | DFS |
BFS, stands for Breadth First Scan. | DFS, which stands for First Search Depth |
For finding the shortest path, BFS uses Queue. | For finding the shortest path, DFS uses Stack. |
It is not ideal for the decision tree used in puzzle games, as BFS considers all neighbours. | DFS is best suited to the decision tree. As with one decision, in order to raise the decision, we need to go further. If we come to a decision, we'll win. |
When the target is nearer to the source, the BFS is higher. | When the goal is far from the source, the DFS is better |
Time BFS Complexity = O(V+E) where vertices are V and edges are E. | DFS Time Complexity is also O(V+E) where vertices are V, and edges are E. |
BFS has been slower than DFS. | DFS is quicker than BFS. |
DFS(G) { for each v in V, //for loop V+1 times { color[v]=white; // V times p[v]=NULL; // V times } time=0; // constant time O(1) for each u in V, //for loop V+1 times if (color[u]==white) // V times DFSVISIT(u) // call to DFSVISIT(v) , at most V times O(V) } DFSVISIT(u) { color[u]=gray; // constant time t[u] = ++time; for each v in Adj(u) // for loop if (color[v] == white) { p[v] = u; DFSVISIT(v); // call to DFSVISIT(v) } color[u] = black; // constant time f[u]=++time; // constant time } |
Step 1: - Initialize all the vertices by setting Flag = 1 Step 2: - Put the starting vertex A in Q and change its status to the waiting state by setting Flag = 0 Step 3: - Repeat through step 5 while Q is not NULL Step 4 : - Remove the front vertex v of Q . process v and set the status of v to the processed status by setting Flag = -1 Step 5: - Add to the rear of Q all the neighbour of v that are in the ready state by setting Flag = 1 and change their status to the waiting state by setting flag = 0 Step 6: - Exit |
BFS(G,s) { for each v in V - {s} // for loop { color[v]=white; d[v]= INFINITY; p[v]=NULL; } color[s] = gray; d[s]=0; p[s]=NULL; Q = ø; // Initialize queue is empty Enqueue(Q,s); /* Insert start vertex s in Queue Q */ while Q is nonempty // while loop { u = Dequeue[Q]; /* Remove an element from Queue Q*/ for each v in Adj[u] // for loop { if (color[v] == white) /*if v is unvisted*/ { color[v] = gray; /* v is visted */ d[v] = d[u] + 1; /*Set distance of v to no. of edges from s to u*/ p[v] = u; /*Set parent of v*/ Enqueue(Q,v); /*Insert v in Queue Q*/ } } color[u] = black; /*finally visted or explored vertex u*/ } } |
∑ |Adj(v)|=O(E) |
|

Step | graph | Remark |
1 |
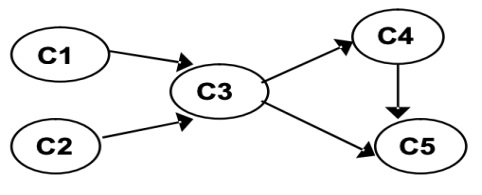
| Insert C1 into stack.
C1 (1) |
2 |
| Insert C2 into stack.
C2 (2) C1 (1) |
3 |
| Insert C4 into stack C4 (3) C2 (2) C1(1) |
4 |
| Insert C5 into stack C5 (4) C4 (3) C2 (2) C1(1) |
5 | NO adjacent vertex for C5, backtrack, unvisited
| Delete C5 from stack C5 (4, 1) C4 (3) C2 (2) C1(1) |
6 | NO adjacent vertex for C4, backtrack, unvisited | Delete C4 from stack C5 (4, 1) C4 (3, 2) C2 (2) C1(1) |
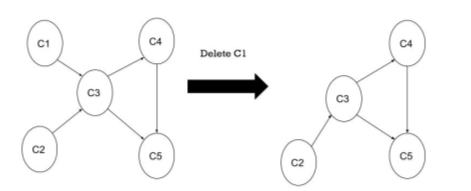
7 | NO adjacent vertex for C3, backtrack, unvisited | Delete C3 from stack C5 (4, 1) C4 (3,2) C2 (2, 3) C1(1) |
8 | NO adjacent vertex for C1, backtrack, unvisited | Delete C1 from stack C5 (4, 1) C4 (3,2) C2 (2, 3) C1(1, 4) |
The stack is empty, but there is an unvisited node, so start the DFS again by arbitrarily selecting an unvisited node as the source. | ||
9 |
| Insert C2 into stack C5 (4, 1) C4 (3,2) C2 (2, 3) C1(1, 4) C2(5) |
10 | NO adjacent vertex for C2, backtrack, unvisited | Delete C2 from stack C5 (4, 1) C4 (3,2) C2 (2, 3) C1(1, 4) C2(5, 5) |
The stack is empty, leaving NO unvisited node, so the algorithm stops. Off order the popping-off order is: C5, C4, C3, C1, C2, List sorted topologically (reverse of pop order): C2, C1 C3 C4 C5 | ||


|
|
|

for j ← 0 to u-l do D[j] ← 0 // init frequencies for i ← 0 to n-1 do D[A[i]-l] ← D[A[i] - l] + 1 // compute frequencies for j ← 1 to u-l do D[j] ← D[j-1] + D[j] // reuse for distribution for i ← n-1 downto 0 do j ← A[i] - l S[D[j] - 1] ← A[i] D[j] ← D[j] - 1 return S
|
13 | 11 | 12 | 13 | 12 | 12 |
Array Values | 11 | 12 | 13 |
Frequencies | 1 | 3 | 2 |
Distribution | 1 | 4 | 6 |
A [5] =
A [4] =
A [3] =
A [2] =
A [1] =
A [0] = | D [0] | D [1] | D [2] |
1 | 4 | 6 | |
1 | 3 | 6 | |
1 | 2 | 6 | |
1 | 2 | 5 | |
1 | 1 | 5 | |
0 | 1 | 5 |
S [0] | S [1] | S [2] | S [3] | S [4] | S [5] |
|
|
| 12 |
|
|
|
| 12 |
|
|
|
|
|
|
|
| 13 |
| 12 |
|
|
|
|
11 |
|
|
|
|
|
|
|
|
| 13 |
|
void horspoolInitocc() { int j; char a; for (a=0; a<alphabetsize; a++) occ[a]=-1; for (j=0; j<m-1; j++) { a=p[j]; occ[a]=j; } } void horspoolSearch() { int i=0, j; while (i<=n-m) { j=m-1; while (j>=0 && p[j]==t[i+j]) j--; if (j<0) report(i); i+=m-1; i-=occ[t[i]]; } }
|
|

|
|
|

|
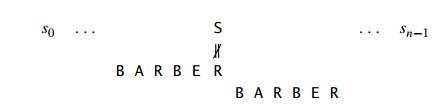
ShiftTable(P [0..m − 1]) //Fills the shift table used by Horspool’s and Boyer-Moore algorithms //Input: Pattern P [0..m − 1] and an alphabet of possible characters //Output: Table[0..size − 1] indexed by the alphabet’s characters and / / filled with shift sizes for i ← 0 to size − 1 do Table[i] ← m for j ← 0 to m − 2 do Table[P [j ]] ← m − 1 − j return Table Time complexity : ● Step of preprocessing in O(m+ п) time and complexity of O(п) space. ● Search process in the time complexity of O(mn). ● The average number of comparisons is between 1/п and 2/(п+1) for a single text character. (п is the number of characters stored)
|




