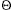 (|K|), even though searching for an element in the hash table still requires only O(1) time. (The only catch is that this bound is for the average time, whereas for direct addressing it holds for the worst-case time.)
(|K|), even though searching for an element in the hash table still requires only O(1) time. (The only catch is that this bound is for the average time, whereas for direct addressing it holds for the worst-case time.)
|
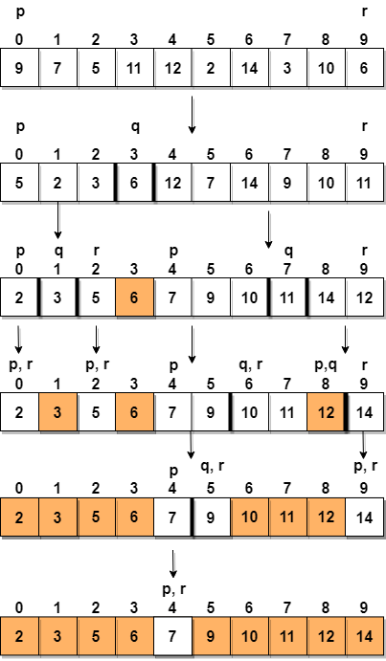
 {0,1, . . . , m - 1} .We say that an element with key k hashes to slot h(k); we also say that h(k) is the hash value of key k. Figure illustrates the basic idea. The point of the hash function is to reduce the range of array indices that need to be handled. Instead of |U| values, we need to handle only m values. Storage requirements are correspondingly reduced.The fly in the ointment of this beautiful idea is that two keys may hash to the same slot--a collision. Fortunately, there are effective techniques for resolving the conflict created by collisions.
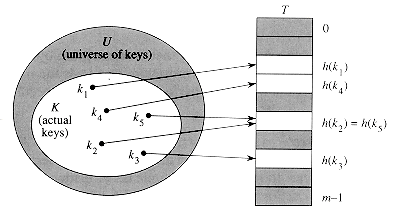
{0,1, . . . , m - 1} .We say that an element with key k hashes to slot h(k); we also say that h(k) is the hash value of key k. Figure illustrates the basic idea. The point of the hash function is to reduce the range of array indices that need to be handled. Instead of |U| values, we need to handle only m values. Storage requirements are correspondingly reduced.The fly in the ointment of this beautiful idea is that two keys may hash to the same slot--a collision. Fortunately, there are effective techniques for resolving the conflict created by collisions.
|
|
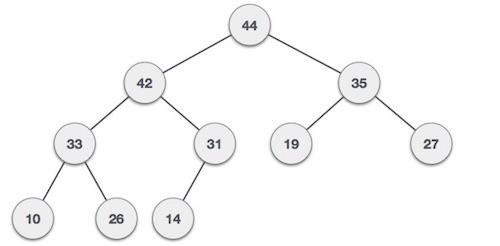
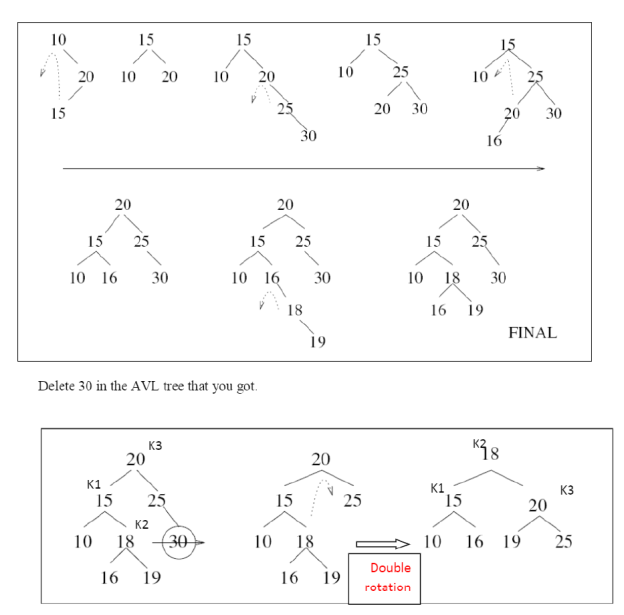
● 1.Liner Probing(this is prone to clustering of data + Some other constrains)
● 2.Quadratic probing
● 3.Double hashing(in short in case of collision another hashing function is used with the key value as an input to identify where in the open addressing scheme the data should actually be stored.)
2. Usage: Usage of either of these techniques is a trade-off between time complexity and size of code. If time complexity is the point of focus, and number of recursive calls would be large, it is better to use iteration. However, if time complexity is not an issue and shortness of code is, recursion would be the way to go.
○ Recursion: Recursion involves calling the same function again, and hence, has a very small length of code. However, as we saw in the analysis, the time complexity of recursion can get to be exponential when there are a considerable number of recursive calls. Hence, usage of recursion is advantageous in shorter code, but higher time complexity.○ Iteration: Iteration is repetition of a block of code. This involves a larger size of code, but the time complexity is generally lesser than it is for recursion.3. Overhead: Recursion has a large amount of Overhead as compared to Iteration.
○ Recursion: Recursion has the overhead of repeated function calls, that is due to repetitive calling of the same function, the time complexity of the code increases manifold.○ Iteration: Iteration does not involve any such overhead.4. Infinite Repetition: Infinite Repetition in recursion can lead to CPU crash but in iteration, it will stop when memory is exhausted.
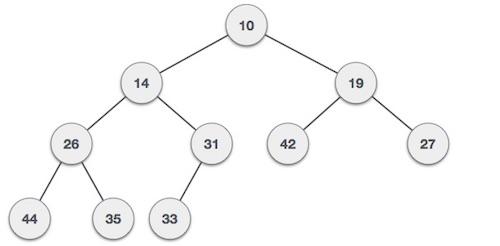
○ Recursion: In Recursion, Infinite recursive calls may occur due to some mistake in specifying the base condition, which on never becoming false, keeps calling the function, which may lead to system CPU crash.○● The left subtree of a node contains only nodes with keys lesser than the node’s key.
● The right subtree of a node contains only nodes with keys greater than the node’s key.
● The left and right subtree each must also be a binary search tree






